3D Diffusion Policy
Generalizable Visuomotor Policy Learning via Simple 3D Representations
Abstract. Imitation learning provides an efficient way to teach robots dexterous skills; however, learning complex skills robustly and generalizablely usually consumes large amounts of human demonstrations. To tackle this challenging problem, we present 3D Diffusion Policy (DP3), a novel visual imitation learning approach that incorporates the power of 3D visual representations into diffusion policies, a class of conditional action generative models. The core design of DP3 is the utilization of a compact 3D visual representation, extracted from sparse point clouds with an efficient point encoder. In our experiments involving 72 simulation tasks, DP3 successfully handles most tasks with just 10 demonstrations and surpasses baselines with a 24.2% relative improvement. In 4 real robot tasks, DP3 demonstrates precise control with a high success rate of 85%, given only 40 demonstrations of each task, and shows excellent generalization abilities in diverse aspects, including space, viewpoint, appearance, and instance. Interestingly, in real robot experiments, DP3 rarely violates safety requirements, in contrast to baseline methods which frequently do, necessitating human intervention. Our extensive evaluation highlights the critical importance of 3D representations in real-world robot learning.
Effectiveness & Generalizability
Effectiveness. We evaluate DP3 on 72 simulated tasks and 4 real-world tasks and observe that DP3 is able to achieve surprising effectiveness in diverse simulated and real-world tasks, including both high-dimensional and low-dimensional control tasks, with a practical inference speed. Notably, for 67 out of 72 simulated tasks, we only use 10 demonstrations; for 4 challenging real-world tasks, we only use 40 demonstrations.
Generalization with few data. We use MetaWorld Reach as an example task, given only • 5 demonstrations. We evaluate 1000 times to cover the 3D space and visualize • successful evaluation points. DP3 learns the generalizable skill in 3D space; Diffusion Policy and IBC only succeed in partial space; BCRNN fails to learn such a simple skill with limited data. Check out more generalization abilities of DP3!
Method
DP3 perceives the environment through single-view point clouds. The sparsely sampled point clouds are encoded into compact 3D representations by a lightweight DP3 encoder. Subsequently, DP3 generates actions conditioning on these 3D representations and the robot states, using a diffusion model as the backbone.
Benchmark
To systematically evaluate the effectiveness and generalizability of DP3, We construct an imitation learning benchmark that consists of diverse simulated and real-world tasks. Both high-dimensional and low-dimensional control tasks are included in the benchmark.
Real-World Tasks
Our real-world benchmark contains 4 challenging tasks: Roll-Up, Dumpling, Drill, and Pour. The first three tasks use an Allegro Hand with 22 DoF and the last task uses a gripper with 7 DoF. These tasks include diverse skills such as deformable object manipulation and tool using. We visualize the 3D point clouds of the tasks and the corresponding robot demonstrations below.
Simulated Tasks
Our simulated tasks contains 72 tasks from 7 benchmarks: Adroit, Bi-DexHands, DexArt, DexDeform, DexMV, HORA, and MetaWorld. Diverse embodiments and tasks are included in the benchmark, such as bi-manual manipulation, deformable object manipulation, articulated object manipulation, and tool using. We sample part of the tasks and also visualize the 3D observations as shown below.
Paper
Latest version: arXiv:2403.03954 [cs.RO] or here.
Robotics: Science and Systems (RSS) 2024

Team






1 Shanghai Qi Zhi Institute 2 Shanghai Jiao Tong University 3 Tsinghua University, IIIS 4 Shanghai AI Lab * Equal contribution
BibTex
@inproceedings{Ze2024DP3,
title={3D Diffusion Policy: Generalizable Visuomotor Policy Learning via Simple 3D Representations},
author={Yanjie Ze and Gu Zhang and Kangning Zhang and Chenyuan Hu and Muhan Wang and Huazhe Xu},
booktitle={Proceedings of Robotics: Science and Systems (RSS)},
year={2024}
}
Task 1: Roll-Up
In the Roll-Up task, the robot needs to wrap the plasticine multiple times to make a roll-up.
Task 2: Dumpling
In the Dumpling task, the robot needs to make a dumpling by wrapping and pinching the plasticine.
Task 3: Drill
In the Drill task, the robot needs to touch the cube with a drill.
Task 4: Pour
In the Pour task, the robot needs to pour out dried meat floss onto the plasticine.
Generalizability
DP3 shows strong generalization abilities in various aspects, including space, appearance, instance, and view.Spatial Generalization
DP3 could better extrapolate in 3D space. We demonstrate this property in the real world, as shown below. We find that baselines fail to generalize to all test positions while DP3 succeed in 4 out of 5 trials.

DP3
Diffusion Policy
Diffusion Policy (Depth)
Appearance Generalization
DP3 is designed to process point clouds without color information, inherently enabling it to generalize across various appearances effectively. As shown below, DP3 consistently exhibits successful generalization to cubes of differing colors, while baseline methods could not achieve. It is noteworthy that the depth-based diffusion policy also does not incorporate color as input. However, due to its lower accuracy on the training object, the ability to generalize is also limited.

DP3
Diffusion Policy

Diffusion Policy (Depth)
*One video is not recorded due to an emergent shut down.
Instance Generalization
Achieving generalization across diverse instances, which vary in shape, size, and appearance, presents a significantly greater challenge compared to mere appearance generalization. As shown below, DP3 effectively manages a wide range of everyday objects. This success can be primarily attributed to the inherent characteristics of point clouds. Specifically, the use of point clouds allows for policies that are less prone to confusion, particularly when these point clouds are downsampled.

DP3
Diffusion Policy
Diffusion Policy (Depth)
View Generalization
Generalizing image-based methods across different views is notably challenging, and acquiring training data from multiple views can be time-consuming and costly. We show that DP3 effectively addresses this generalization problem when the camera views are altered slightly.

DP3
Diffusion Policy
Diffusion Policy (Depth)
Safety Violations from Baselines
In real-world experiments, we surprisingly observe that image-based and depth-based diffusion policies often deliver unpredictable behaviors in real-world experiments, which necessitates human termination to ensure robot safety. This situation is defined as safety violation. Interestingly, DP3 rarely violates the safety in our experiments, showing that DP3 is a practical and hardware-friendly method for real robot learning.
Why Safety is Important for Robotics?
 You might notice that a left Allegro hand is used in our high-resolution videos, whereas in other videos, a right Allegro hand appears.
You might notice that a left Allegro hand is used in our high-resolution videos, whereas in other videos, a right Allegro hand appears.
What happened is the right hand we initially used was broken 😣, maybe due to a lot of safety violations. Consequently, we had to collect all the demonstrations again with a left hand.
The lucky part is DP3 does not require hundreds of demonstrations so it is not very (but still) time-consuming to recollect the demonstrations.
One More Thing: Simple DP3
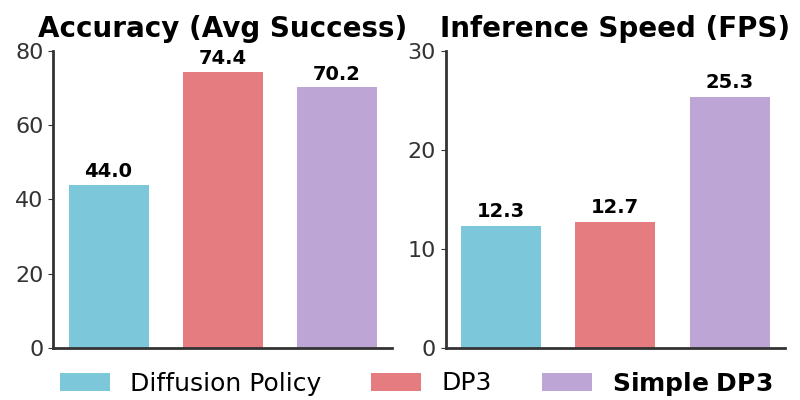 To enhance the applicability of DP3 in real-world robot learning, we simplify the policy backbone of DP3, which is identified as one critical factor that impacts inference speed.
The refined version, dubbed Simple DP3, offers 2x inference speed while maintaining high accuracy, as shown on the right. The efficiency stems from removing the redundant components in the UNet backbone. The implementation of Simple DP3 is available in our released code.
To enhance the applicability of DP3 in real-world robot learning, we simplify the policy backbone of DP3, which is identified as one critical factor that impacts inference speed.
The refined version, dubbed Simple DP3, offers 2x inference speed while maintaining high accuracy, as shown on the right. The efficiency stems from removing the redundant components in the UNet backbone. The implementation of Simple DP3 is available in our released code.
Contact
If you have any questions, please feel free to contact Yanjie Ze.